上下文工程 —— 解锁大模型真正潜力的关键
上下文工程 —— 解锁大模型真正潜力的关键
上下文工程解决什么问题
现阶段,基于 RAG 想提高生成式问答效果,简单地 “检索 - 拼接 - 生成” 往往并不能得到最优结果。可能会遇到:
检索到的信息不准确或与问题无关。
即使检索到了相关信息,LLM 却忽略了它,依然依赖自身知识产生幻觉。
上下文太长,导致 LLM 无法关注到关键信息,或者因超过令牌限制而被截断。
此时,就需要上下文工程来解决这些问题。
上下文工程是一门设计和优化输入给 LLM 的上下文信息的艺术与科学,旨在最大化 LLM 的推理能力和输出质量。
上下文工程所包含的范围
一句话,只要是模型生成回答之前所看到的一切信息,都是上下文工程的范畴。
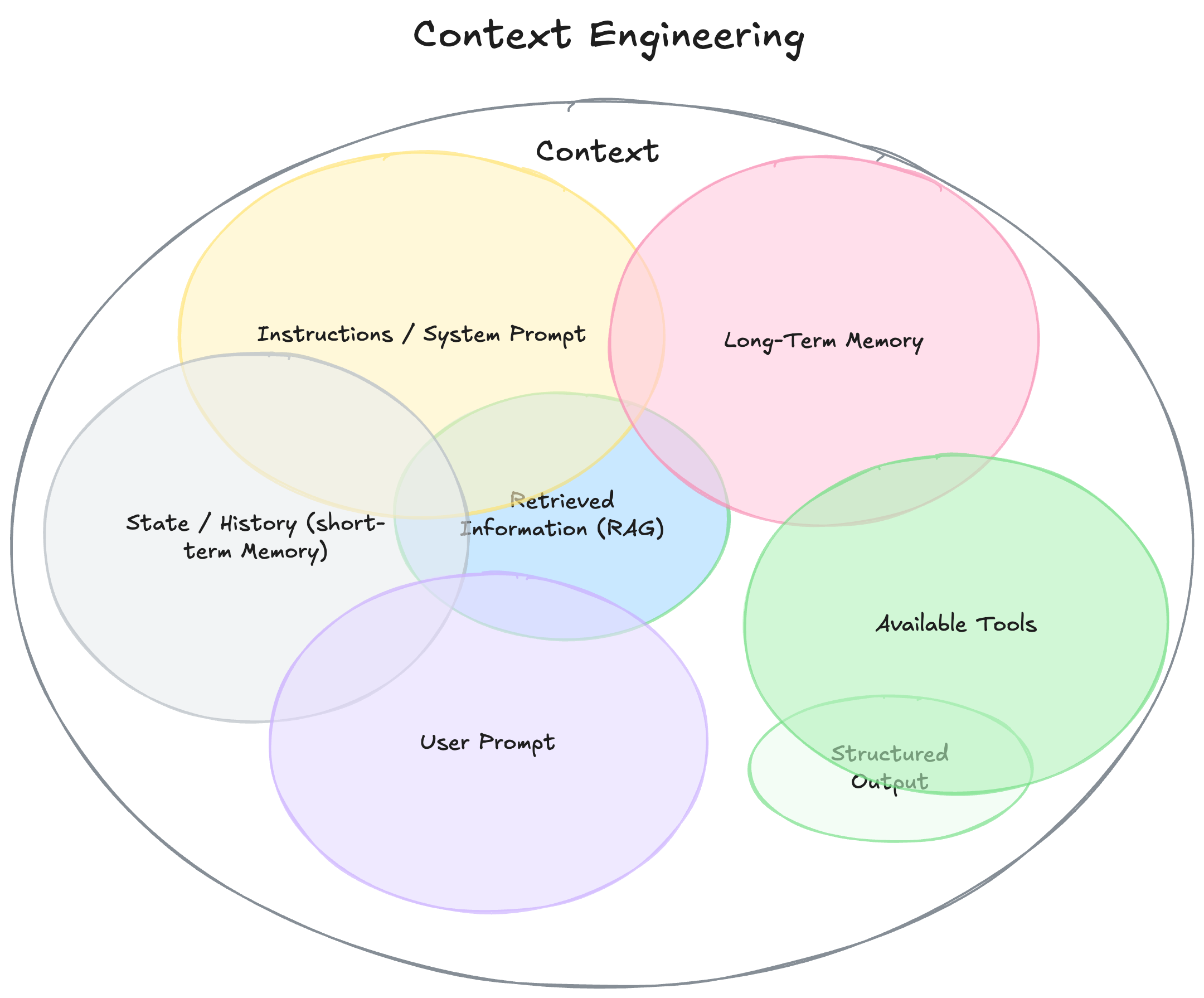
其核心工作贯穿以下流程:
1. 检索前的数据准备(知识库层面)
分块(Chunking)
如何将长文档切割成更小的片段至关重要。块太大可能包含多主题干扰信息,太小则可能丢失关键上下文。工程师需要根据文档类型(如MD文档、PDF表格、代码)调整块大小和重叠(Overlap)策略。
数据清洗与增强
清除无关内容(页眉、页脚)、标准化格式、为文本添加元数据(如标题、发布日期、部门),这些元数据可以极大提升检索的精准度。
选择嵌入模型(Embedding Model)
不同的模型在不同领域和语言上表现各异。为特定领域微调嵌入模型或选择专有模型,可以显著提升检索相关性。
2. 检索中的优化(查询与搜索层面)
查询重写/扩展(Query Reformulation/Expansion)
用户的原始查询可能很模糊。使用 LLM 对查询进行重写、扩展同义词或生成假设性答案(HyDE),可以大幅提升检索效果。
检索策略
除了简单的相似性搜索,还可以融合关键词搜索(BM25)进行混合搜索(Hybrid Search),兼顾语义匹配和精确术语匹配。高级技术如重新排序(Re-ranking)模型,可以对初步检索结果进行二次精排,将最相关的结果排在前面。
3. 生成前的上下文构建(提示词层面)—— 这是上下文工程的核心
上下文压缩与摘要
检索到的多个文档片段可能包含冗余信息。可以使用 LLM 先对这些片段进行摘要或去重,只将最精炼的信息放入上下文,节省宝贵的令牌。
结构化与排序
将检索到的上下文以清晰、有条理的方式呈现给 LLM。例如,按相关性排序,或使用明确的章节标题(如 “## 相关文档1:... ## 相关文档2:...”),帮助 LLM 更好地理解和利用这些信息。
设计系统提示(System Prompt)
这是上下文工程的精髓。系统提示用于明确指导 LLM 如何利用上下文。
糟糕的提示
“请根据以下文档回答问题。”
工程化的提示
“你是一个专业的客服助手。请严格根据提供的参考文档来回答问题。如果文档中的信息不足以回答问题,请明确回答 ‘根据已有信息无法回答该问题’,切勿编造信息。你的回答需清晰引用文档来源。参考文档如下:...”
通过上述精细化的操作,上下文工程确保了注入 LLM 的信息是 高相关、高质量、易理解 的,从而最终引导 LLM 生成 更准确、更可靠、更符合要求 的答案。
上下文工程落地的策略
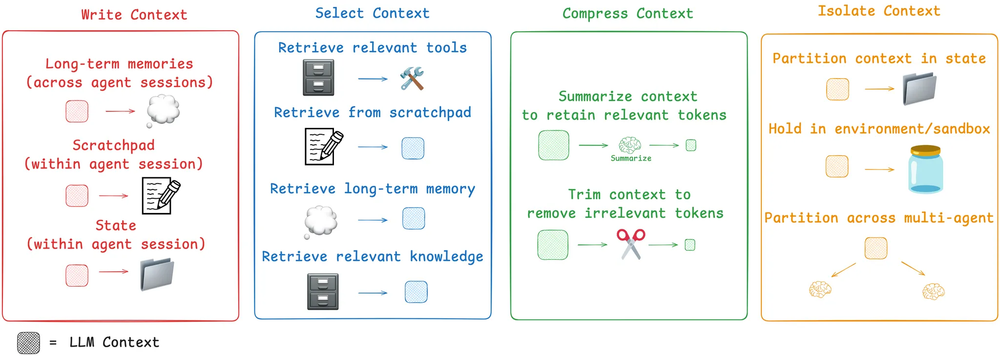
上面四个落地策略来自 Langchain 发布的一篇博客文章,归纳四个词就是 “写入 - 筛选 - 压缩 - 隔离”,有点像 SQL 的增-删-改-查。
本质上,我们现在的调优工作,其实都在上下文工程这个范畴,这里面涉及到的 Scratchpads、Memories、Tools、Knowledge、Context Summarization、Multi-agent、Context 等。
再回归到问题的本质,如果只是需要提高大语言模型回答问题的准确率和质量,engineering 这里面有非常大的想象空间,RAG 只是一个 context engineering 非常粗糙的一个工程方案。
Andrej Karpathy 一个推特火了一个新词,就能让这个工作成为业界一个追逐范式,并且发展成一个工程学科,这就是业界影响力!
上下文工程不等同于上下文
两者的目的都是通过引入额外的、动态的信息,使系统的输出与当前情境更相关、更精准。
在我们 MCP 应用中,目前我们一个稍微复杂点的问题,MCP 最多能调 个 Tools,但实际调用 个 Tools 就能解决这个问题。一些技术报告也实验证明了更多的工具、更多的补充信息、更长的上下文并不一定会产生更好的响应。上下文过载可能会导致智能体以意想不到的方式失败。上下文可能会变得有害、分散注意力、令人困惑或产生冲突。
在我们 A2A 应用中,智能体之前也是依赖上下文来收集信息,但综合发现一旦涉及到多轮对话上下文,动作智能体之间的关系就容易出错,因为一旦涉及到相互协作和相互依赖,信息之间就会出现错乱。
我个人理解,在比较高级一点的应用,这两项技术应该是相互融合的,一方面要让生成的回答更 准确、可信、相关;另一方面,追求个性化、情境化的智能输出。
上下文工程前瞻思考
如题,Context Engineering 是解锁大模型真正潜力的关键,未来落地落地思考会暂时会围绕以下两点去展开:
1)大语言模型(LLM)作为智能体的大脑,那上下文工程就是这个大脑的 “外脑”,它未来要自主决定何时需要检索、检索什么、如何根据初步结果进行下一步操作,这一定是自动化的。
2)突破 RAG 系统限制,追求对上下文的深度加工,而 RAG 只提供了 “检索” 这一种获取方式。加工包括:总结、翻译、格式化、过滤、排序、压缩等,远非简单的 “检索并拼接”。
如今在大模型时代,提示工程(Prompt Engineering)已然不能完全解放人工写提示过程,但上下文工程(Context Engineering)是有可能彻底告别人工调优的。
参考资料:
[1] The New Skill in AI is Not Prompting, It's Context Engineering (https://www.philschmid.de/context-engineering)
[2] Context Engineering (https://blog.langchain.com/context-engineering-for-agents/)
[3] The rise of "context engineering" (https://blog.langchain.com/the-rise-of-context-engineering/)